Introduction to CRDTs
December 21, 2021 · 8 min read

CRDT (conflict-free replicated data type) is a data structure that can be replicated across multiple computers in a network, where replicas can be updated independently and in parallel, without the need for coordination between replicas, and with a guarantee that no conflicts will occur.
CRDT is often used in collaborative software, such as scenarios where multiple users need to work together to edit/read a shared document, database, or state. It can be used in database software, text editing software, chat software, etc.
- What problems does CRDT solve?
- Origins
- A simple CRDT case
- Introduction to the Principle
- Comparison of CRDT and OT
- Addressed and Unresolved Issues
- Start Using CRDTs Today
- Extended reading
What problems does CRDT solve?
For example, a scenario where multiple users edit the same document online at the same time

This scenario requires that each user sees the same content, even after concurrent edits by different users (e.g. two users changing the title at the same time), which is known as consistency. (To be precise, CRDT satisfies the eventual consistency, see below for more details)

Users can use CRDT even when they are offline. They can be back on sync with others the network is restored. It also supports collaboratively editing with other users via P2P. It is known as partitioning fault tolerance. This allows CRDT to support decentralized applications very well: synchronization can be done even without a centralized server.
Origins
The formal definition of CRDT first appears in Marc Shapiro’s 2011 paper Conflict-free replicated data types (but Woot in 2006 is probably the earliest study). The motivation for the proposal is that the conflict resolution design of Eventual Consistency is difficult, few articles give design guidance suggestions, and randomly designed solutions are error-prone. So this paper proposes a simple, theoretically proven way to achieve Eventual Consistency, i.e., CRDT.
(PS: Marc Shapiro actually wrote a paper Designing a commutative replicated data type in 2007. In 2011, he reworded commutative into conflict-free in 2011, expanding the definition of commutative to include state-based CRDT)
According to CAP theorem, it is impossible for a distributed computing system to perfectly satisfy the following three points at the same time.
- Consistency: each read receives the result of the most recent write or reports an error; it behaves as if it is accessing the same piece of data
- Availability: every request gets a non-error response - but there is no guarantee that the data fetched is up-to-date
- Partition tolerance: the ability of a distributed system to continue functioning properly even when communication between its different components is lost or delayed, resulting in a partition or network failure.
If the system cannot achieve data consistency within the time limit, it means that partitioning has occurred and a choice must be made between C and A for the current operation, so “perfect consistency” is in conflict with “perfect availability”.
CRDTs do not provide “perfect consistency”, but Strong Eventual Consistency (SEC). This means that site A may not immediately reflect the state changes from site B, but when A and B synchronize their messages they both regain consistency and do not need to resolve potential conflicts (CRDT mathematically prevents conflicts from occurring). Strong Eventual Consistency does not conflict with Availability and Partition Tolerance. CRDTs provide a good CAP tradeoff.
 CRDT satisfies A + P + Eventual Consistency; a good tradeoff under CAP
CRDT satisfies A + P + Eventual Consistency; a good tradeoff under CAP
(PS: In 2012, Eric Brewer, author of the CAP theorem, wrote an article CAP Twelve Years Later: How the “Rules” Have Changed, explaining that the description of the “two out of three CAP features” is actually misleading, and that the CAP actually prohibits perfect availability and consistency in a very small part of the design space, i.e., in the presence of partitions; in fact, the design of the tradeoff between C and A is very flexible. A good example is CRDT.)
A simple CRDT case
We can use a few simple examples to get a general idea of how CRDTs achieve Strong Eventual Consistency.
Grow-only Counter
How can we count the number of times something happens in a distributed system without locking?
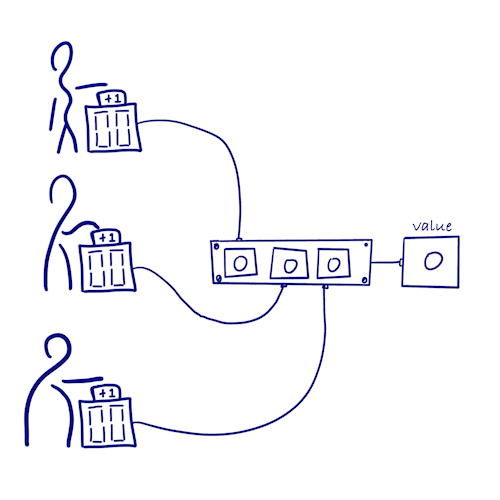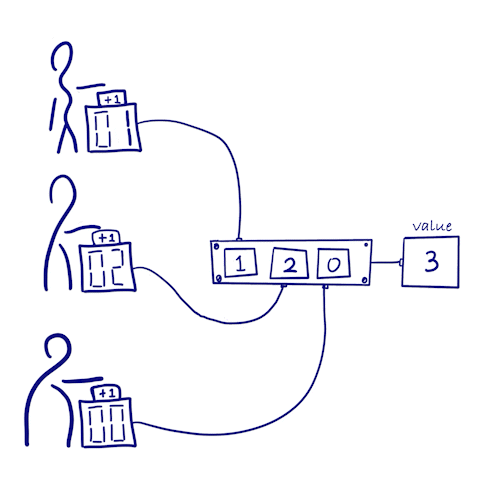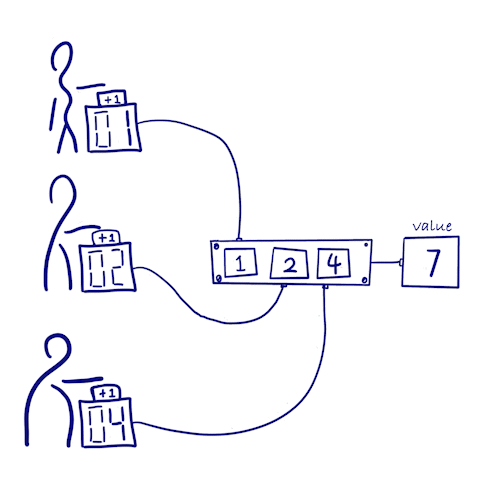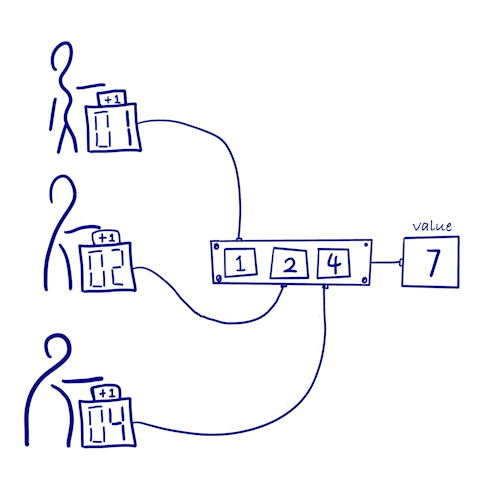
- Let each copy increments only its own counter => no locking synchronization & no conflicts
- Each copy keeps the count values of all other copies at the same time
- Number of occurrences = sum of count values of all copies
- Since each copy only updates its own count and does not conflict with other counters, this type satisfies consistency after message synchronization
Grow-only Set
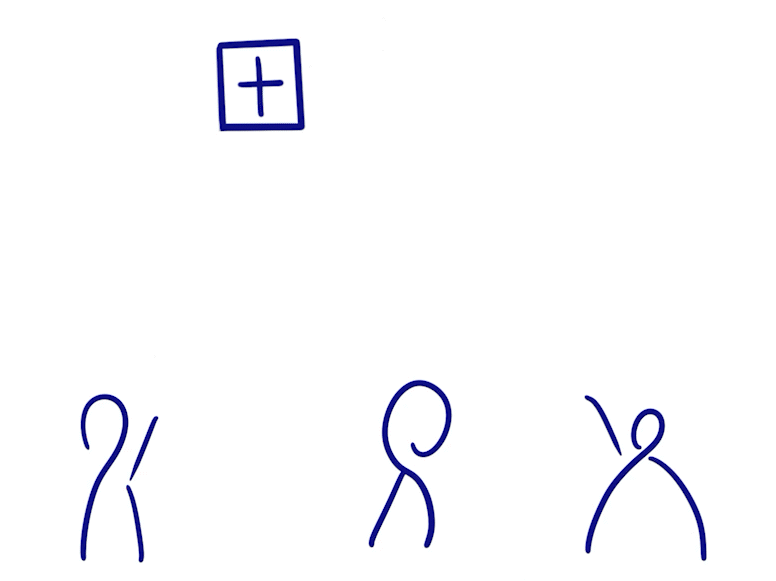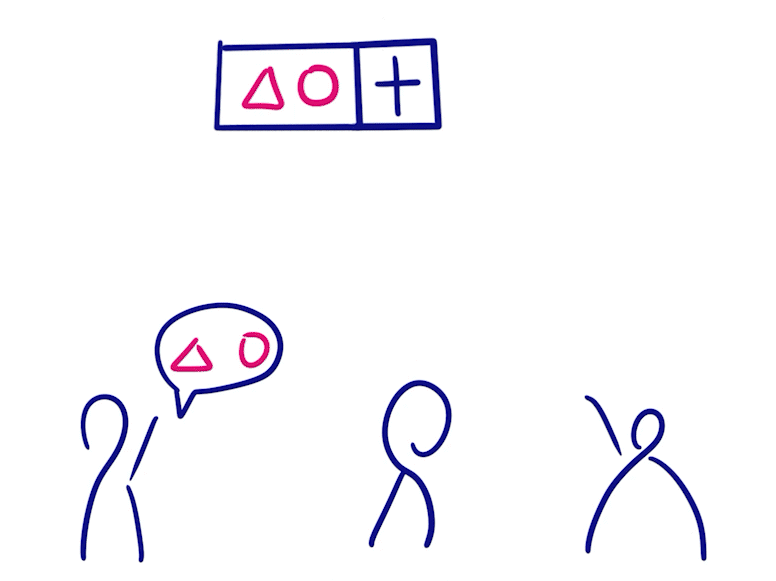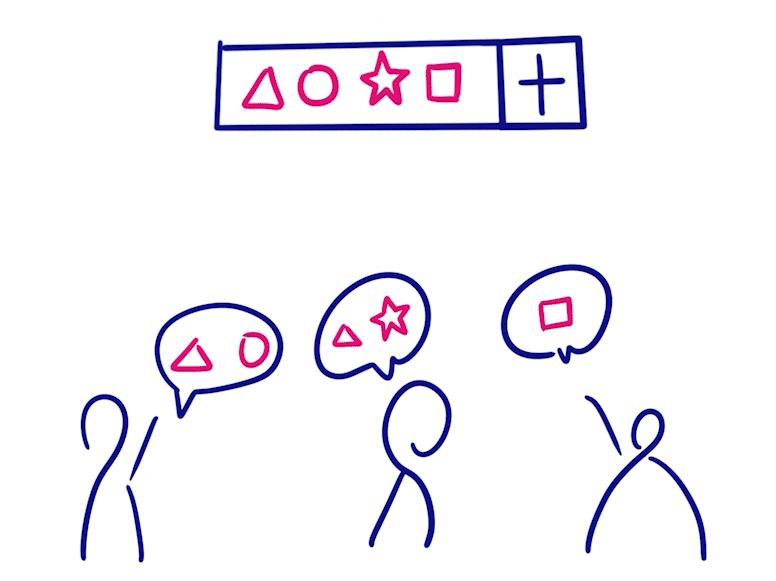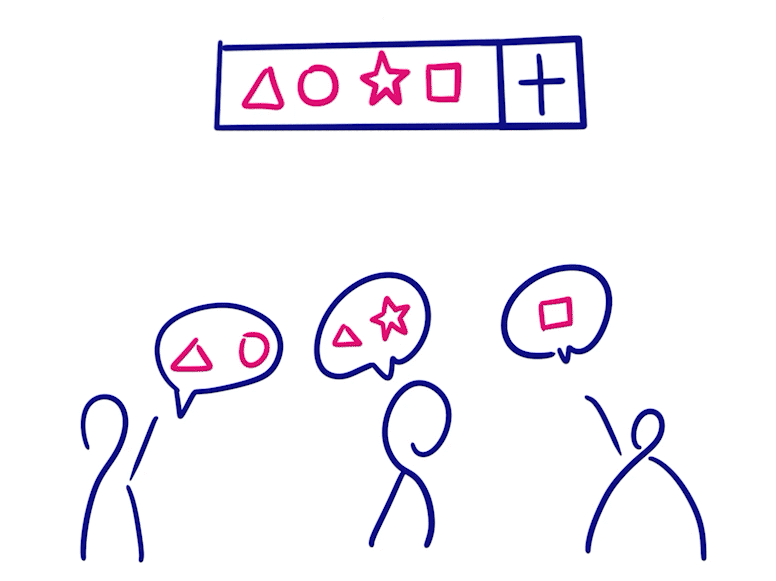
- The elements in a Grow-only Set can only be increased and not decreased
- To merge two such states, you only need to do a merge set
- This type satisfies consistency after message synchronization because there are no conflicting operations since the elements only grow and do not decrease.
Both of these methods are CRDTs, and they both satisfy the following properties
- They can both be updated independently and concurrently, without coordination (locking) between replicas
- There is no possibility of conflict between multiple updates
- Final consistency can always be guaranteed
Introduction to the Principle
There are two types of CRDTs: Op-based CRDTs and State-based CRDTs. This article focuses on the concept of Op-based CRDTs.
Op-based CRDTs operate on the principle that if two users perform identical sequences of operations, the final state of the document should also be identical. To achieve this, each user saves all the operations performed on the data (Operations) and synchronizes these Operations with other users to ensure a consistent final state. A critical challenge in this approach is ensuring the order of Operations remains consistent, especially when parallel modification operations occur. To address this, Op-based CRDTs require that all possible parallel Operations be commutative, satisfying the final consistency requirement.
If you want to see how State-based CRDT works, and other more in-depth content welcome to read the next chapter of this series How to design CRDT.
Comparison of CRDT and OT
Both CRDT and Operation Transformation(OT) can be used in online collaborative applications, with the following differences
| OT | CRDT |
|---|---|
| OT relies on a centralized server for collaboration; it is extremely difficult to make it work in a distributed environment | CRDT algorithm can be used to synchronize data through a P2P approach synchronization |
| The earliest paper on OT was presented in 1989 | The earliest paper on CRDT appeared in 2006 |
| The OT algorithm is designed with higher complexity to ensure consistency | The CRDT algorithm is designed to be simpler to ensure consistency |
| It is easier to design OT to preserve user intent | It is more difficult to design a CRDT algorithm that preserves user intent |
| OT does not affect document size | CRDT documents are larger than the original document data |
More related discussions can be found in
Addressed and Unresolved Issues
This section was last updated in December 2021
Why do we still see OT algorithms rather than CRDTs in most collaborative software? First, because CRDT is a relatively young method compared to OT, and some of the difficulties have only been solved in recent years, e.g.
- How to make the merge result of conflicting edits meet the user’s intents as much as possible (this problem is often easier in OT than in CRDT)
- Related paper Interleaving anomalies in collaborative text editors.
- CRDT Move
- How to achieve high-performance CRDTs
There is still a lot of research to be done in the following areas
- CRDTs often have tombstone data that is difficult to recycle, how can we do it better?
- How to reduce the overhead of updating CRDT documents?
Start Using CRDTs Today
You don’t need to design and implement CRDT algorithms from scratch (CRDTs can be easily implemented poorly). Instead, you can build your application directly on top of open-source CRDT projects such as Automerge, Yjs, and the one I am currently developing, Loro. You can view their performance comparison here.
Extended reading
- Marc Shapiro, Nuno Preguiça, Carlos Baquero and Marek Zawirski, Conflict-free replicated data types (2011 paper formally defining CRDTs)
- Petru Nicolaescu, Kevin Jahns, Michael Derntl and Ralf Klamma, Near Real-Time Peer-to-Peer Shared Editing on Extensible Data Types (Yjs paper)
- Martin Kleppmann, Alastair R. Beresford, A Conflict-Free Replicated JSON Datatype (Automerge)
- Martin Kleppmann, CRDTs The Hard Parts
- Seph, 5000x faster CRDTs: An Adventure in Optimization
Go to the next chapter: How to Design a CRDT Algorithm
