CRDT 简介
December 21, 2021 · 12 min read

CRDT (conflict-free replicated data type) 无冲突复制数据类型,是一种可以在网络中的多台计算机上复制的数据结构,副本可以独立和并行地更新,不需要在副本之间进行协调,并保证不会有冲突发生。
CRDT 常被用在协作软件上,例如多个用户需要共同编辑/读取共享的文档、数据库或状态的场景。在数据库软件,文本编辑软件,聊天软件等都可以用到它。
CRDT 解决了什么问题
例如多用户在线同时编辑同一篇文档的场景

这个场景要求每个用户看到的内容都是一样的,即使在用户出现冲突编辑后(例如两个用户同时修改标题,两个请求同时到达服务器)也不会产生两个版本,这被称为一致性。(准确地说 CRDT 满足的是最终一致性,见下文详述)

CRDT 让用户即使离线也可使用,并在恢复网络后能继续和所有人同步至一致的状态。也可以和其他用户通过 P2P 的方式一起协同编辑。这被称为分区容错性。这让 CRDT 可以很好地支持去中心化的应用:即使没有中心化服务器各端之间也能完成同步。
起源
CRDT 的正式定义出现在 Marc Shapiro 2011 年的论文 Conflict-free replicated data types 中(而2006 的Woot可能是最早的研究)。提出的动机是因为最终一致性(Eventual Consistency) 的冲突解决设计很困难,很少有文章给出设计指导建议,而随意的设计的方案容易出错。所以这篇文章提出了简单的、理论证明的方式来达到最终一致性,也就是 CRDT。
(PS: 其实 Marc Shapiro 在 2007 年就写了一篇 Designing a commutative replicated data type,2011 年将 commutative 变成了 conflict-free,在其定义上扩充了 State-based CRDT)
根据 CAP 定理,对于一个分布式计算系统来说,不可能同时完美地满足以下三点:
- 一致性(Consistency): 每一次读都会收到最近的写的结果或报错;表现起来像是在访问同一份数据
- 可用性(Availability): 每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据
- 分区容错性(Partition tolerance): 以实际效果而言,分区相当于对通信的时限要求
系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择,所以「完美的一致性」与「完美的可用性」是冲突的。
CRDT 不提供「完美的一致性」,它提供了 强最终一致性 Strong Eventual Consistency (SEC) 。这代表进程 A 可能无法立即反映进程 B 上发生的状态改动,但是当 A B 同步消息之后它们二者就可以恢复一致性,并且不需要解决潜在冲突(CRDT 在数学上就不让冲突发生)。而「强最终一致性」是不与「可用性」和「分区容错性」冲突的,所以 CRDT 同时提供了这三者,提供了很好的 CAP 上的权衡。
 CRDT 满足 A + P + Eventual Consistency;是 CAP 下很好的权衡
CRDT 满足 A + P + Eventual Consistency;是 CAP 下很好的权衡
(PS: 在 2012 年,CAP 定理的作者 Eric Brewer 写了一篇文章CAP Twelve Years Later: How the “Rules” Have Changed,解释了“CAP 特性三选二” 的描述其实具有误导性,实际上 CAP 只禁止了设计空间的很小一部分即存在分区时的完美可用性和一致性;而实际上在 C 和 A 之间的权衡的设计非常灵活,CRDT 就是一个很好的例子。)
简单的 CRDT 案例
我们可以通过几个简单的例子来大致理解 CRDT 类算法达到 Strong Eventual Consistency 的思路。
Grow-only Counter
如何在分布式系统中不加锁地统计一件事情的发生次数呢?
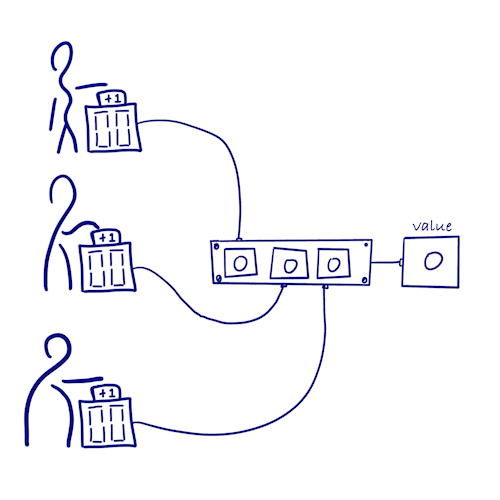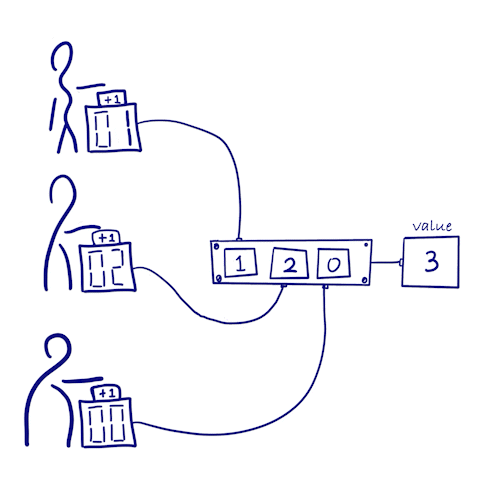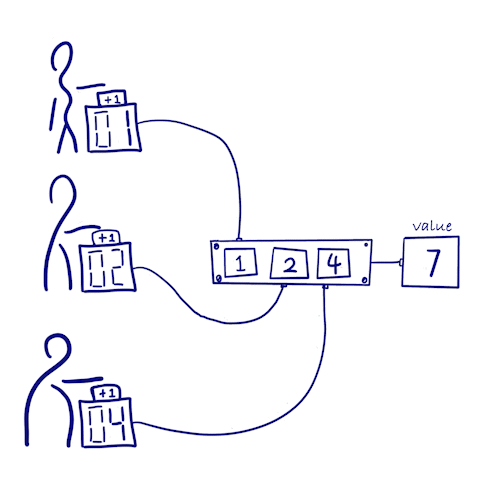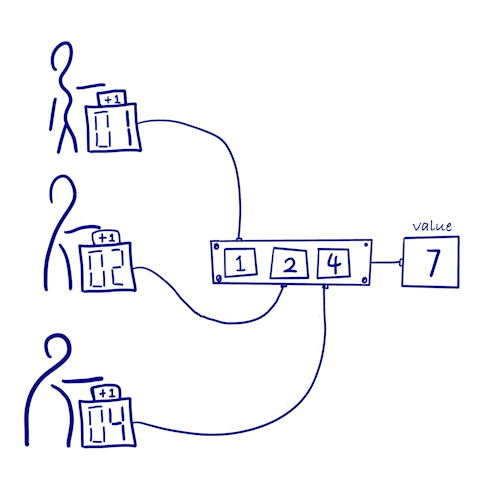
- 让每个副本只能递增自己的计数器 => 不用加锁同步 & 不会发生冲突
- 每个副本上同时保存着所有其他副本的计数值
- 发生次数 = 所有副本计数值之和
- 因为每个副本都只会更新自己的计数值,不会与其他计数器产生冲突,所以该类型在消息同步后便满足一致性
Grow-only Set
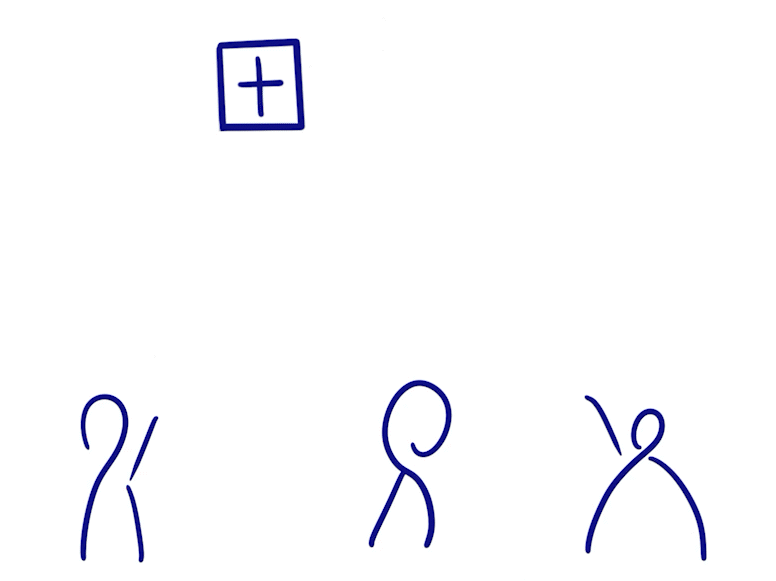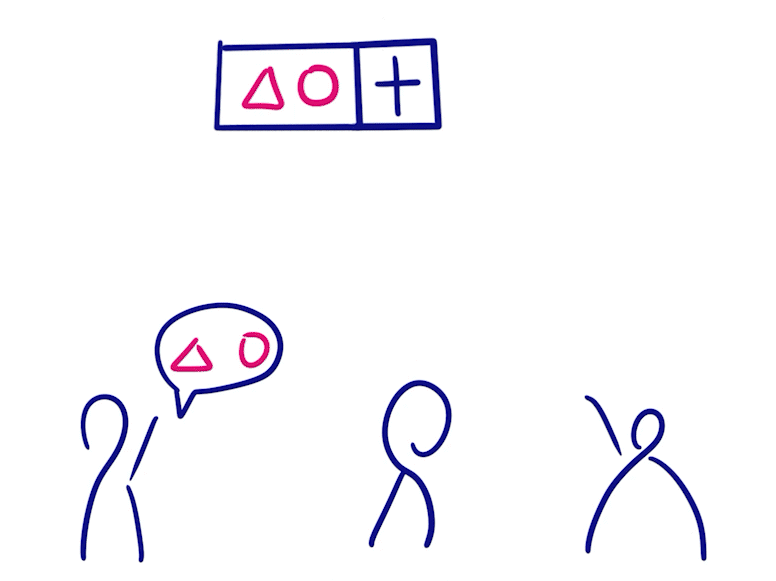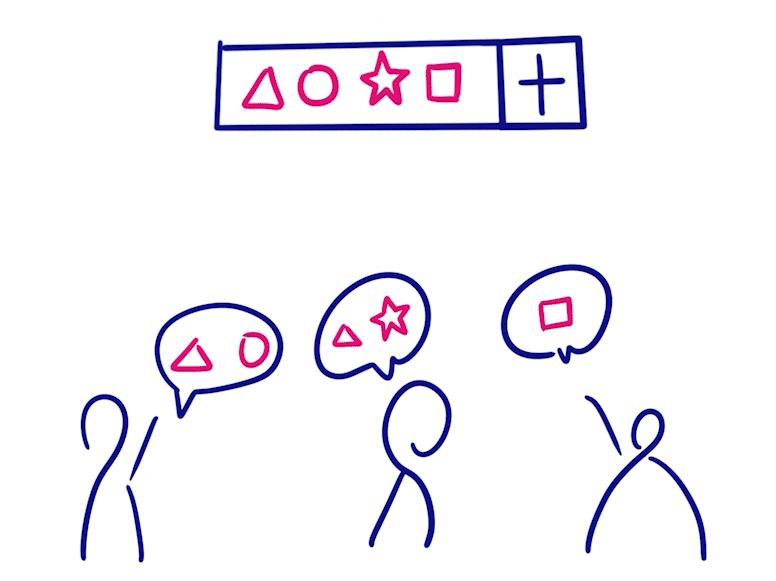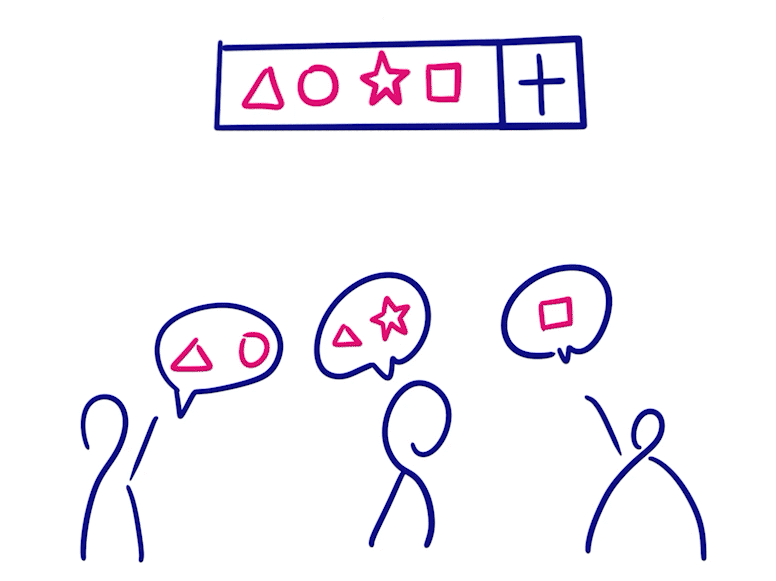
- Grow-only Set 当中的元素是只能增加不能减少的
- 将两个这样的状态合并就只需要做并集
- 因为元素只增不减,不存在冲突操作,所以该类型在消息同步后便满足一致性
上述两种方法都是 CRDT。他们都满足以下性质
- 他们都可以被独立并发地更新,而不需要副本之间进行协调(加锁)
- 多个更新之间不可能发生冲突
- 总是可以保证最终一致性
原理简介
CRDT 有两种类型:Op-based CRDT 和 State-based CRDT,此处仅介绍 Op-based 的思路。
Op-based CRDT 的思路为:如果两个用户的操作序列是完全一致的,那么最终文档的状态也一定是一致的。所以索性各个用户保存对数据的所有操作(Operations),用户之间通过同步 Operations 来达到最终一致状态。但我们怎么保证 Op 的顺序是一致的呢,如果有并行的修改操作应该谁先谁后?所以 Op-based CRDT 要求可能并行的 Op 都是可交换的,由此就可以满足最终一致性的要求。
如果想看 State-based CRDT 的原理,以及其他更深入的内容欢迎阅读本系列下一章如何设计 CRDT。
CRDT 和 OT 的对比
CRDT 和 Operation Transformation(OT) 都可以被用于在线协作型的应用中,二者的差别如下
| OT | CRDT |
|---|---|
| OT 依赖中心化服务器完成协作; 如果想要让它在分布式环境中工作就异常困难 | CRDT 算法可以通过 P2P 的方式完成数据的同步 |
| OT 最早的论文于 1989 年提出 | CRDT 最早的论文出现于 2006 年 |
| 为保证一致性,OT 的算法设计时的复杂度更高 | 为保证一致性,CRDT 算法设计更简单 |
| OT 的设计更容易保留用户意图 | 设计一个保留用户意图的 CRDT 算法更困难 |
| OT 不影响文档体积 | CRDT 文档比原文档数据更大 |
更多相关讨论可看
已解决的问题 & 目前还存在的问题
此部分内容最后更新时间为 2021 年 12 月
为什么目前在协作软件中大多数看到的还是应用 OT 算法而不是 CRDT 呢?首先因为 CRDT 这类方法相比 OT 还比较年轻,而且有些难点近几年才被比较好地解决,例如:
- 如何让存在冲突的编辑的合并结果尽量符合用户预期 (这个问题上用 OT 设计往往比 CRDT 更容易,CRDT 本身只保证一致性,让合并的结果符合预期是需要专门设计的)
- CRDT Move
- 如何实现高性能的 CRDT
而目前在以下方面的研究还有待展开
- CRDT 中常常存在难以回收的墓碑数据,如何才能更好地回收 CRDT 的墓碑?
- 如何降低更新 CRDT 文档的开销?
现在开始使用 CRDT
你不用自己从头开始设计和实现 CRDTs 算法(CRDT 很容易被实现得很糟糕)。你可以直接基于开源 CRDTs 项目来搭建你的应用例如 Automerge, Yjs 以及我正在研发的 Loro。你可以在这里查看它们的性能对比。
扩展阅读
- Marc Shapiro, Nuno Preguiça, Carlos Baquero and Marek Zawirski, Conflict-free replicated data types (2011 正式定义 CRDT 的论文)
- Petru Nicolaescu, Kevin Jahns, Michael Derntl and Ralf Klamma, Near Real-Time Peer-to-Peer Shared Editing on Extensible Data Types ( Yjs 论文)
- Martin Kleppmann, Alastair R. Beresford, A Conflict-Free Replicated JSON Datatype (Automerge)
- Martin Kleppmann, CRDTs The Hard Parts
- Seph, 5000x faster CRDTs: An Adventure in Optimization
前往下一章:如何设计 CRDT 算法
